Hoe ontwikkel je een end-to-end dataproduct?
Een end-to-end dataproduct beslaat uit het volledige proces: van data-acquisitie tot de uiteindelijke presentatie en het gebruik door de eindgebruikers. In dit artikel sta ik stil bij elk stap van dit proces.

Geschreven door:

Dit alles is gebaseerd op een stabiele, efficiënte data-infrastructuur en ondersteund door doordachte data-managementprocessen. Bij het ontwikkelen van dit soort producten komt behoorlijk wat kijken. Laten we het proces stap voor stap doorlopen.
De flow van data
Data extractie
Dit is de eerste cruciale stap waarbij data vanuit verschillende bronnen wordt verzameld. Of het nu gaat om databases, API’s, sensoren of andere systemen, het ontsluiten van data moet snel, consistent en betrouwbaar gebeuren. Dit betekent dat we robuuste pipelines ontwikkelen waarbij we gewogen afwegingen maken tussen full-loads en delta-loads en rekening houden met backfilling en verversnelheden. Vaak willen klanten binnen enkele minuten nieuwe data kunnen inzien en met onze kennis en de techniek van tegenwoordig, is dit ook haalbaar.
Data transformatie
Nadat de data is ontsloten, wordt deze getransformeerd, opgeschoond en geprepareerd voor gebruik in Business Intelligence (BI) of Data Science toepassingen. Dit houdt in dat we ruwe data omzetten naar een gestructureerd en bruikbaar formaat. Hier worden onder andere foutcorrecties uitgevoerd, duplicaten verwijderd en data verrijkt.
Data opslag
Vervolgens wordt de getransformeerde data opgeslagen. Hierbij maken we gebruik van technieken zoals partitioning en indexing om de data snel toegankelijk te maken. Dit zorgt ervoor dat BI-omgevingen efficiënt de data kunnen inladen en incrementeel kunnen verversen zonder prestatieverlies. Ook kijken we in deze stap naar Data Warehouse en Data Lakehouse principes en hoe deze het beste aansluiten op de wensen van de klant.
Data modelleren
In deze stap leggen we de relaties tussen verschillende tabellen en systemen. Dit modelleert de data zodanig dat het logisch, snel en intuïtief te gebruiken is. Het datamodel vormt de ruggengraat van elke BI-oplossing en is cruciaal voor accurate en slimme analyses en rapportages. In het datamodel is time-intelligence voor ons een essentieel onderdeel. Time-intelligence stelt ons namelijk in staat om complexe tijdsgebonden analyses uit te voeren, zoals trendanalyses, seizoensgebonden patronen en vergelijkingen over verschillende tijdsperioden.
Data visualisatie
De gemodelleerde data wordt vervolgens gepresenteerd in dashboards en rapportages. Dit helpt gebruikers om inzichten te verkrijgen en geïnformeerde beslissingen te nemen. Goede visualisaties maken complexe data begrijpelijk en toegankelijk.
Distributie
Voordat de end-to-end dataflow gereed is moet er al worden nagedacht over de manier waarop de data gepresenteerd wordt aan de eindgebruikers. Dit is een essentieel onderdeel van het dataproduct ontwerp en is onder andere (mede) bepalend voor de BI tool keuze. Met PowerBI, één van onze favoriete tools, kan de data op diverse manieren beschikbaar worden gesteld:
- Via de PowerBI Service
- Via de mobiele app van PowerBI
- Via PowerBI Embedded
De keuze hangt sterk af van waar de eindgebruikers zich bevinden. Indien de rapportages gemaakt zijn voor gebruikers die zich binnen de organisatie bevinden, kun je prima af met de PowerBI Service. Maar als de gebruikers zich buiten de eigen organisatie bevinden, wordt dit al omslachtig doordat iedereen en licentie en account van de organisatie moet hebben.
Daarom kiezen we momenteel vaak voor PowerBI Embedded. Hiermee kunnen we veilig en relatief eenvoudig rapportages integreren in webpagina’s. Deze flexibiliteit brengt ook enige complexiteit met zich mee. Voor PowerBI Embedded is namelijk een enigszins dure Fabric Capacity nodig. Gelukkig is deze goed op- en af te schalen, maar dit vereist extra logica en dus ook onderhoud binnen het product. Om volledig zelf in controle te kunnen zijn, ontwikkelen wij bij voorkeur eigen web portals. Hiermee kunnen eindgebruikers de rapportages via een zelf gehoste website bekijken.
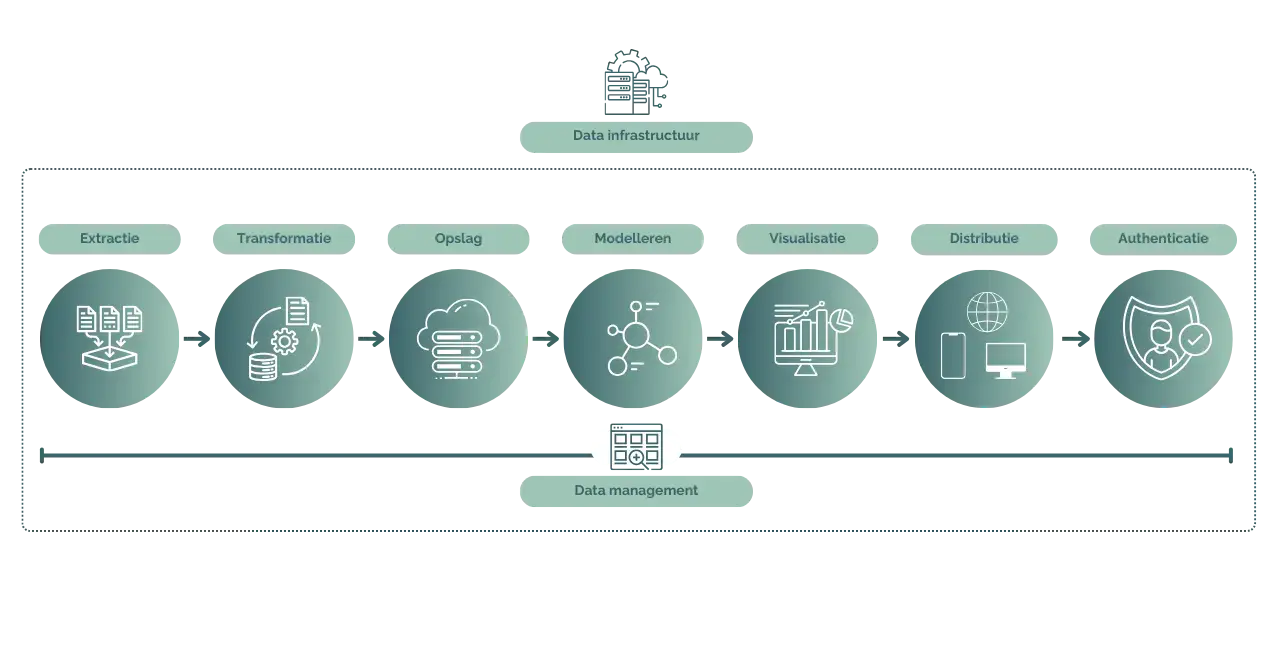
Authenticatie
Doordat wij eigen web portals ontwikkelen, zijn we ook in controle over de authenticatie en autorisatie. Diverse lagen binnen deze concepten zorgen ervoor dat de juiste gebruiker toegang krijgt tot de juiste rapportages en daarbinnen ook de data te zien krijgt die voor hem of haar bestemt is.
Allereerst moet een eindgebruiker bij ons bekend zijn en inloggen (MFA) via het portaal. Daarnaast moet deze gebruiker toegang hebben tot een rapportage (zogenoemde doelgroepen in een PowerBI App) die ook nog eens beveiligd is op rijniveau (RLS), en tabelniveau (OLS).
Waar RLS zich beperkt tot toegang op data op basis van de rijen, beperkt OLS zich tot toegang op basis van specifieke objecten, zoals tabellen of kolommen, binnen een dataset. Hierdoor hebben gebruikers alleen toegang tot de onderdelen die voor hen zijn geautoriseerd.
Data Infrastructuur
Het gehele proces wordt ondersteund door een solide data-infrastructuur. Over de keuzes en afwegingen voor de infrastructuur zouden we boekwerken kunnen schrijven, maar daar heb ik gelukkig geen tijd voor en daarom probeer ik het maar beknopt toe te lichten.
De infrastructuur wordt afgestemd op het doel van het eindproduct en uiteraard niet andersom. Waar wij met name op letten is:
- Schaalbaarheid: De infrastructuur moet kunnen meegroeien en afschalen met de hoeveelheid data en het aantal gebruikers. Zij moet diverse soorten data en workloads aankunnen, zoals batch- en real-time verwerking.
- Betrouwbaarheid: De infrastructuur moet consistente prestaties bieden en minimale downtime garanderen.
- Beveiliging: De infrastructuur moet voldoen aan alle relevante beveiligingsnormen en wetgeving, inclusief data encryptie en toegangscontrole.
- Toegankelijkheid: De mate waarin een klant zelf mee ontwikkeld bepaald ook in grote maten de keuzes op technisch vlak. De infrastructuur moet gemakkelijk toegankelijk zijn voor alle gebruikers, ongeacht hun locatie of technische vaardigheden (tot in zekere mate).
- Kosten
Onze engineers hebben o.a. kennis en ervaring met Microsoft Azure als cloud-platform en de inrichting ervan vraagt om specifieke technische kennis en expertise: van Identity and Access Management (IAM), resource management en monitoring tot DevOps protocollen voor de uitrol van de componenten. De keuze is reuze en het is een tijdrovend en complex proces om de juiste componenten voor je product te kiezen. Om dit wat tastbaarder te maken, hieronder een rijtje van componenten (en dan heb ik niet eens over de tools & technieken) die wij momenteel gebruiken voor onze klant BAA waarbij wij een end-to-end dataproduct implementeren:
- App Service en App Service Plan: Hosten Docker containers (webportal, API, onze data Fetcher)
- Container Registry: Opslag Docker Image
- SQL Server en Database: Opslag van data
- Storage Account: Opslag van data
- Managed Identities: Integratie en authenticatie
- Private endpoints en DNS zone: Beveiliging
- Network Interface: Beveiliging
- VNET: Beveiliging
- Fabric Capacity: PowerBI Embedded
- Email service: Versturen alerts en notificaties
- Application Insights: Logging en monitoring
Data Management
Een stevige datamanagement fundering is noodzakelijk om grip en inzicht te houden op de data, zodat we consistent blijven voldoen aan de kwaliteits- en beveiligingseisen. Zo zijn er een aantal datamanagement principes die we volgen bij de ontwikkeling van een end-to-end dataproduct:
- Data governance: Duidelijke richtlijnen en verantwoordelijkheden voor het beheer van data, waar we ook specifieke aandacht richten aan reporting goverance.
- Data kwaliteit: We maken gebruik van een datakwaliteit framework en voeren regelmatig kwaliteitscontroles uit om ervoor te zorgen dat de data accuraat en betrouwbaar is en blijft.
- Schaalbaarheid: We ontwerpen de data infrastructuur zodanig dat deze kan meegroeien met de hoeveelheid data en het aantal gebruikers.
- Beveiliging en compliance: Ook zorgen we ervoor dat de data-infrastructuur voldoet aan alle relevante wet- en regelgeving op het gebied van data privacy en beveiliging.
Door deze stappen te volgen en de juiste principes toe te passen, kunnen we een krachtig en betrouwbaar end-to-end dataproduct creëren dat voldoet aan de behoeften van de organisatie en haar gebruikers.
Uiteraard hebben we bij Metriek voor dit soort implementaties de juiste mensen nodig met genoeg ervaring. Alle profielen uit de data driehoek, waar Marijn Nieboereerder over heeft geschreven, zijn essentieel.
Dus:
- Ben jij een data-expert en bouw jij graag mee aan dit soort projecten?
- Wil je meer weten over één van de bovenstaande onderdelen van dit artikel?
- Wil je meer weten over hoe wij waarde aan jouw organisatie kunnen leveren met de ontwikkeling van end-to-end dataproducten?
Stuur een berichtje naar Marijn Nieboer of mij (Bart Bijlsma) en ontdek wat er mogelijk is.
Lees meer artikelen.

Het verhaal achter Metriek
Metriek is gebouwd op een simpele visie: gelukkige data-experts, vrij van randzaken, presteren op hun best. Dit is precies waar oprichters Bart Bijlsma en Marijn Nieboer in geloven. Ontdek het verhaal achter Metriek.

De vrijheid van een zzp’er gecombineerd met de gezelligheid van gelijkgestemde
Twijfelen tussen freelancen of in loondienst? Bij Metriek vond ik de perfecte mix: de vrijheid en beloning van een zzp’er, maar mét collega’s, gezelligheid en zekerheid. 🚀

Van twijfels naar take-off: Rob’s sprong in het diepe
Rob twijfelde over zijn vaste baan, maar het idee van ondernemen vond hij ook spannend. Toch sprong hij – en landde soepel bij Metriek én Transavia. Na een tijdje zonder laptoptas, maar met backpack rond te reizen in Azië, landt Rob straks weer bij Metriek met een mooie opdracht bij Stedin!
Bekijk onze vacatures.
Data krijgt pas echt waarde zodra mensen de ruimte krijgen en zich goed voelen. Wij doen er alles aan om voor onze data-experts die ideale omgeving te creëren. We kiezen bewust voor drie kennisgebieden waarin onze oprichters ervaren zijn en hebben daarvoor onderstaande vacatures.


AI engineer
- Utrecht
- €7.000 – €11.000 p/m
- WO
- Fulltime

Data engineer
- Utrecht
- €7.000 – €11.000 p/m
- HBO
- Fulltime

BI expert
- Utrecht
- €7.000 – €11.000 p/m
- HBO
- Fulltime

Datamanagement expert
- Utrecht
- €7.000 – €11.000 p/m
- HBO
- Fulltime
Meer weten?
Ben je benieuwd naar ons of heb je een specifieke vraag over een vacature? Neem dan even contact op met Marijn.

Meer weten?
Ben je benieuwd naar ons of heb je een specifieke vraag over een vacature? Neem dan even contact op met Marijn.
Meer weten?
Ben je benieuwd naar ons of heb je een specifieke vraag over een vacature? Neem dan even contact op met Marijn.